1 University of California, Berkeley 2 Facebook AI Research
Abstract
Model-based control is a popular paradigm for robot navigation because
it can leverage a known dynamics model to efficiently plan robust robot trajectories.
However, it is challenging to use model-based methods in settings where the
environment is a priori unknown and can only be observed partially through onboard sensors on the robot. In this work, we address this short-coming by coupling
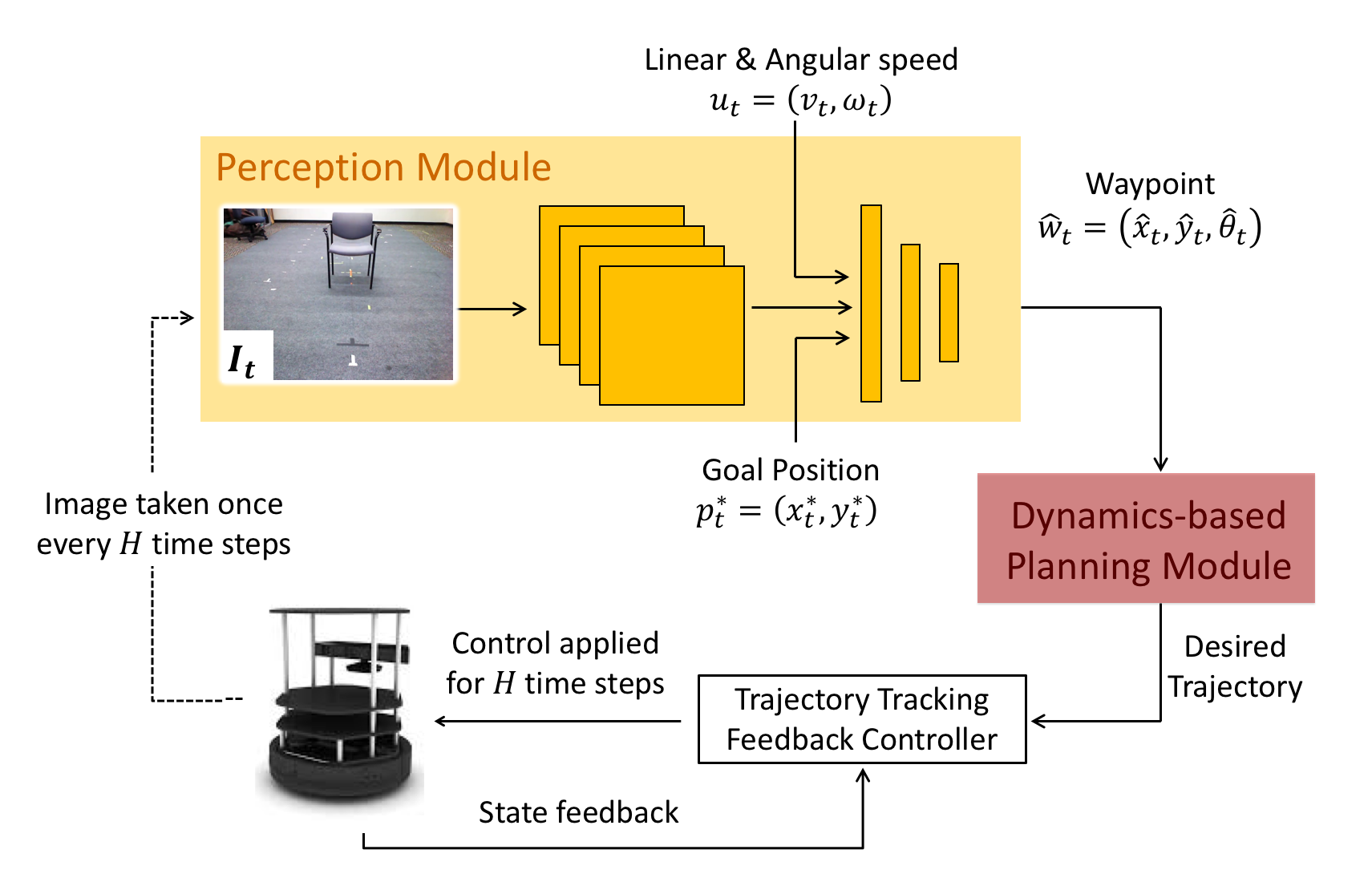
model-based control with learning-based perception. The learning-based perception
module produces a series of waypoints that guide the robot to the goal via a collisionfree path. These waypoints are used by a model-based planner to generate a smooth
and dynamically feasible trajectory that is executed on the physical system using
feedback control. Our experiments in simulated real-world cluttered environments
and on an actual ground vehicle demonstrate that the proposed approach can reach
goal locations more reliably and efficiently in novel environments as compared to
purely geometric mapping-based or end-to-end learning-based alternatives. Our
approach does not rely on detailed explicit 3D maps of the environment, works well
with low frame rates, and generalizes well from simulation to the real world.
Paper
Bansal, Tolani, Gupta, Malik, Tomlin
Combining Optimal Control and Learning for Visual Navigation in Novel Environments
Metrics We evaluate LB-WayPtNav against a comparable end-to-end method and a purely geometric method which uses depth images to estimate an occupancy map of the environment for use in planning via Model Predictive Control (MPC). For the geometric method we compare against both an agent with memory which estimates an occupancy grid based on all the depth images thus far and one that is reactive and estimates an occupancy grid based only on its current view of the environment. All methods are tested on a set of 185 navigational goals in a previously unseen test environment. Our method is approximately 20-25% more successful on these new goals than the end-to-end method. The success rate of LB-WayPtNav, which itself is reactive, is comparable to that of the Mapping (memoryless) baseline. The remaining three metrics are computed on the subset of test goals on which all methods are successful. We find that the model based method navigates to the goal region 1.5 to 2 times as quickly as the end-to-end method with average acceleration approximately half that of the end-to-end method and average jerk approximately 1/20th that of the end-to-end method. LB-WayPtNav is comparable to the mapping based methods in terms of time to reach goal, acceleration, and jerk.
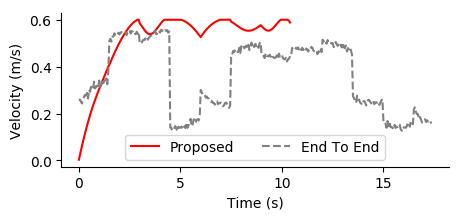
Control Profiles The proposed method produces significantly smoother control profiles than the end-to-end method which are much easier to track on a real physical system. The jerky profiles learned by the end-to-end method could lead to increased probability of hardware failure on a real system as well. Additionally, these jerky control profiles would lead to dramatically increased power usage and thus decreased battery life.
Learned Visual Semantics We find that, through the training process, the agent learns generalizable visual semantics of indoor office environments (i.e. exiting a room by first locating the door and then moving through it, going around a chair that is only partially visible, locating and moving into a hallway to then move into a room connected to this hallway). The agent exhibits this behavior in visually diverse scenarios where providing such supervision explicitly can be very difficult.
Hardware Experiments
We deploy our simulation trained algorithm on a Turtlebot 2 to test on real-world navigational scenarios. Each experiment is visualized from three different viewpoints, however the robot only sees the "First Person View" (also labeled Robot View). The other two viewpoints are provided for context only. We do not train or finetune our algorithm in any way on real data. All experiments are shown in realtime.
Metrics In real-world experiments LB-WayPtNav continues to perform well, however performance of the mapping based methods degrades considerably due to errors in depth estimation on shiny/matte objects (bike frames, tires, computer monitors, etc.), on thin/intricate objects (power cables, chair legs), and in the presence of strong infared light (sunlight).
Videos
Experiments 1-5 We demonstrate that our method is able to leverage the benefits of learned visual semantics and model based control in a variety of real world settings including navigating cluttered hallways (Experiments 1 and 2), cluttered rooms (bikes, chairs, tables, etc.) (Experiments 1 and 3), and leaving a room through a doorway (Experiment 3) in diverse lighting conditions (Experiment 4). Given the reactive nature of our algorithm the robot is also somewhat robust to moving obstacles (Experiment 5).
Failure Modes of End-to-End and Mapping-Based Methods
The End-To-End Method tends to fail in cases where aggressive, yet nuanced control profiles are needed. The Mapping-Based method fails in cases where the depth sensor fails to correctly image the environment (e.g. thin wires, matte and shiny materials, bright sunlight, etc.).
Acknowledgements
This research is supported in part by the DARPA Assured Autonomy program under agreement number FA8750-18-C-0101, by NSF under the CPS Frontier project VeHICaL project (1545126), by NSF grants 1739816 and 1837132, by the UC-Philippine-California Advanced Research Institute under project IIID-2016-005, by SRC under the CONIX Center, and by Berkeley Deep Drive.
This webpage template was borrowed from some colorful folks.