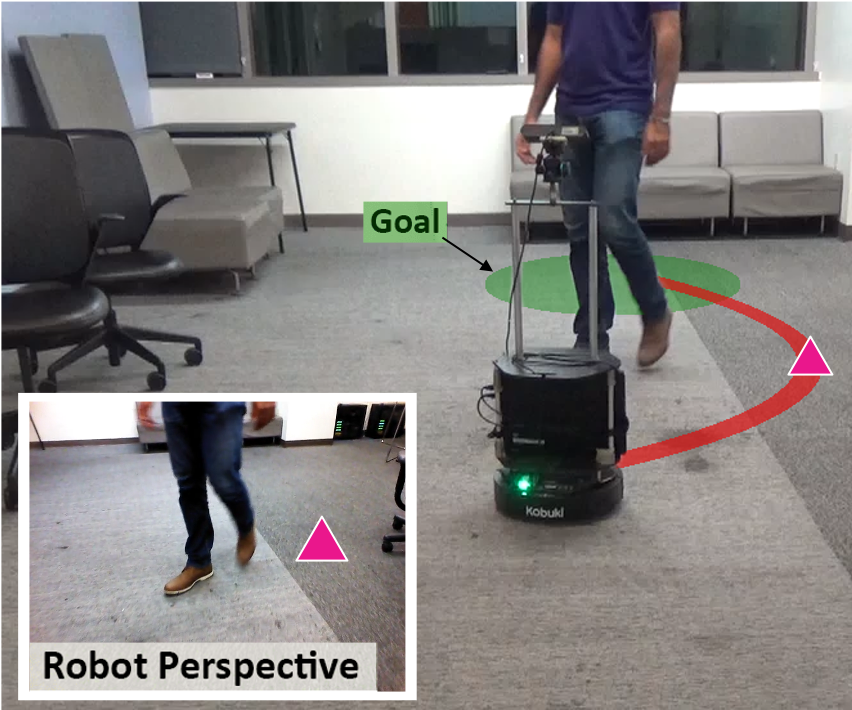
1 University of California, Berkeley 2 Google Brain Research
Abstract
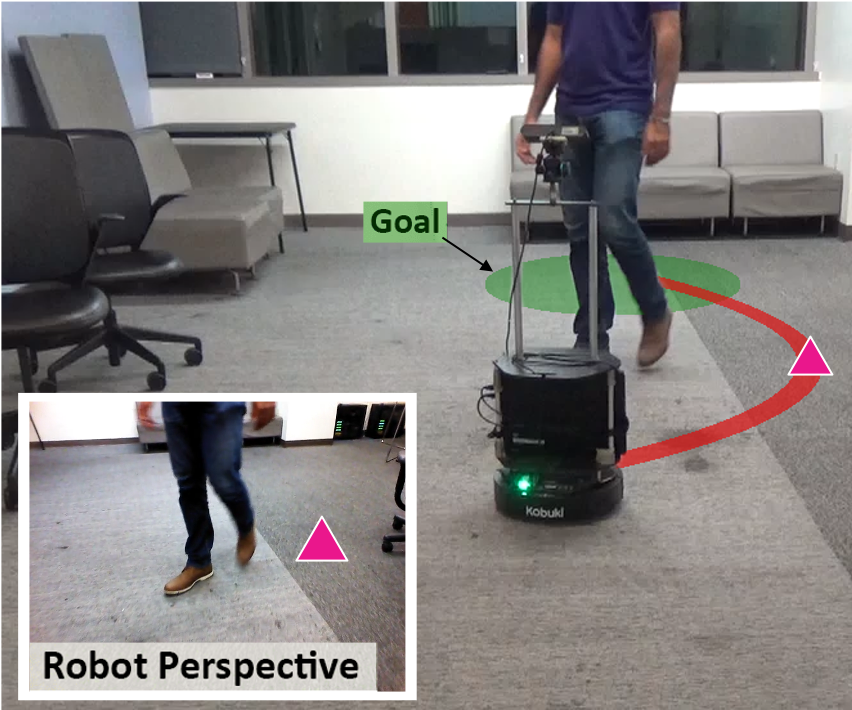
Real world navigation requires robots to operate in unfamiliar, dynamic environments, sharing spaces with humans.
Navigating around humans is especially difficult because it requires predicting their future motion, which can be quite challenging.
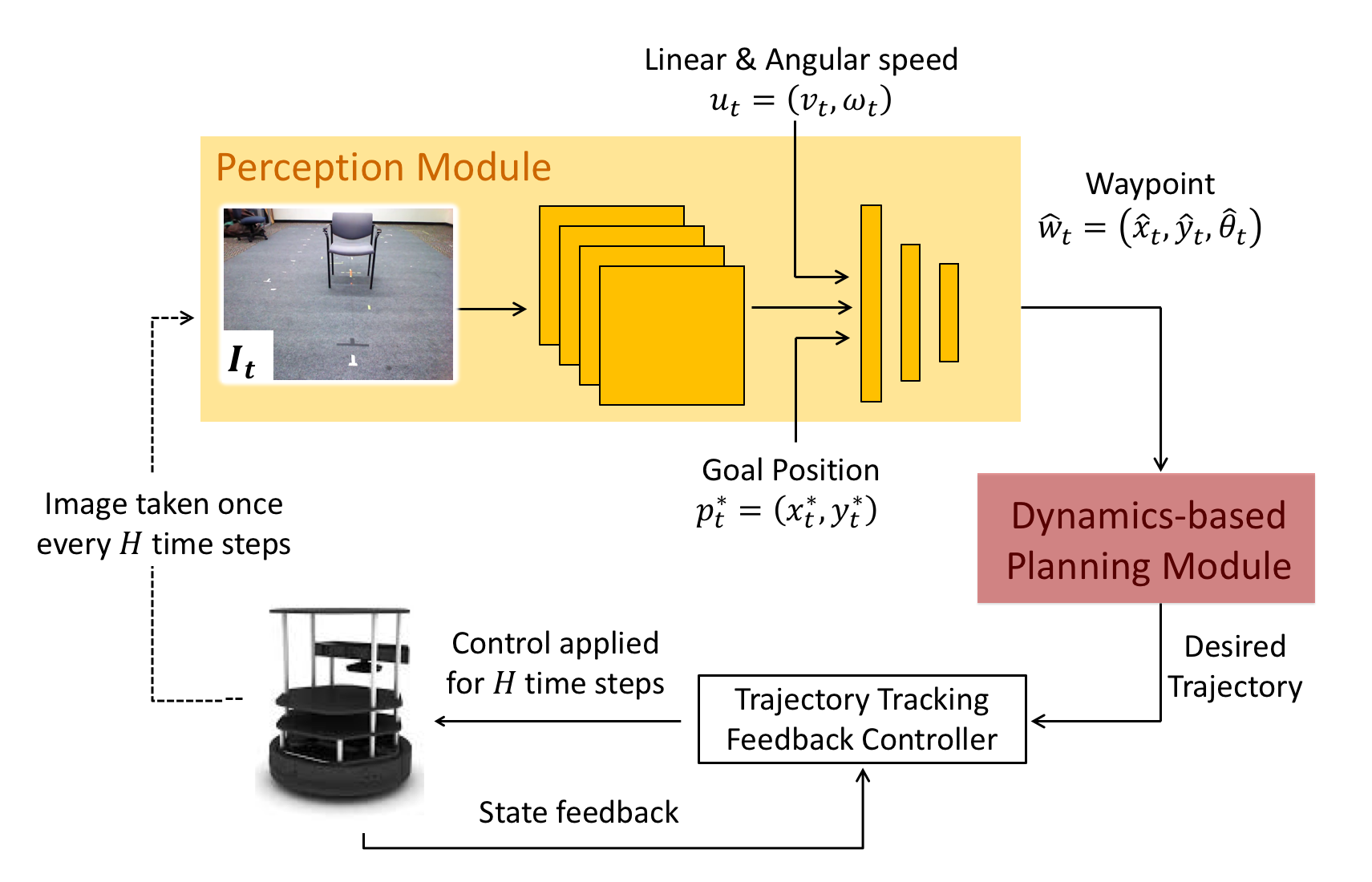
We propose a novel framework for navigation around humans which combines learning-based perception with model-based optimal control.
Specifically, we train a Convolutional Neural Network (CNN)-based perception module which maps the robot's visual inputs to a waypoint, or next desired state. This waypoint is then input into planning and control modules which convey the robot safely and efficiently to the goal.
To train the CNN we contribute a photo-realistic bench-marking dataset for autonomous robot navigation in the presence of humans. The CNN is trained using supervised learning on images rendered from our photo-realistic dataset. The proposed framework learns to anticipate and react to peoples' motion based only on a monocular RGB image, without explicitly predicting the future human motion.
Our method generalizes well to unseen buildings and humans in both simulation and real world environments.
Furthermore, our experiments demonstrate that combining model-based control and learning leads to better and more data-efficient navigational behaviors as compared to a purely learning based approach.
Paper
Tolani, Bansal, Faust, Tomlin
Visual Navigation Among Humans With Optimal Control as a Supervisor
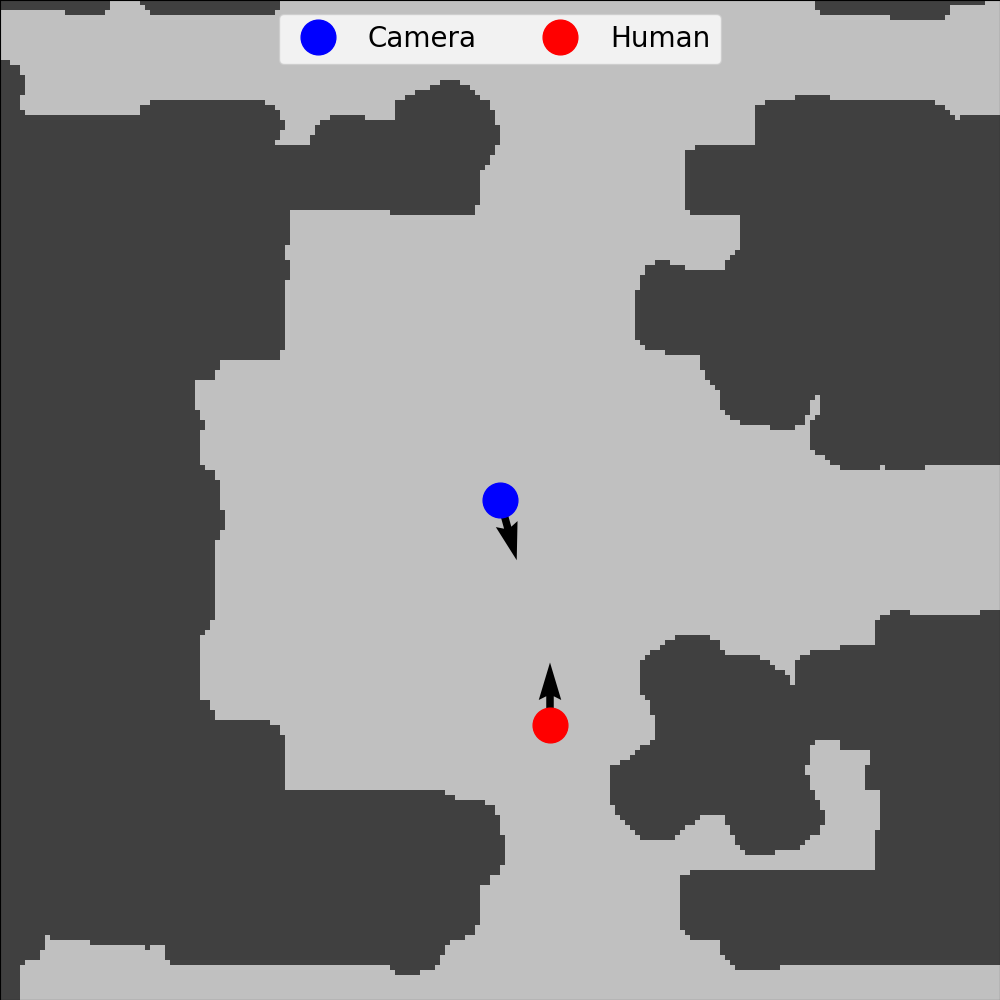
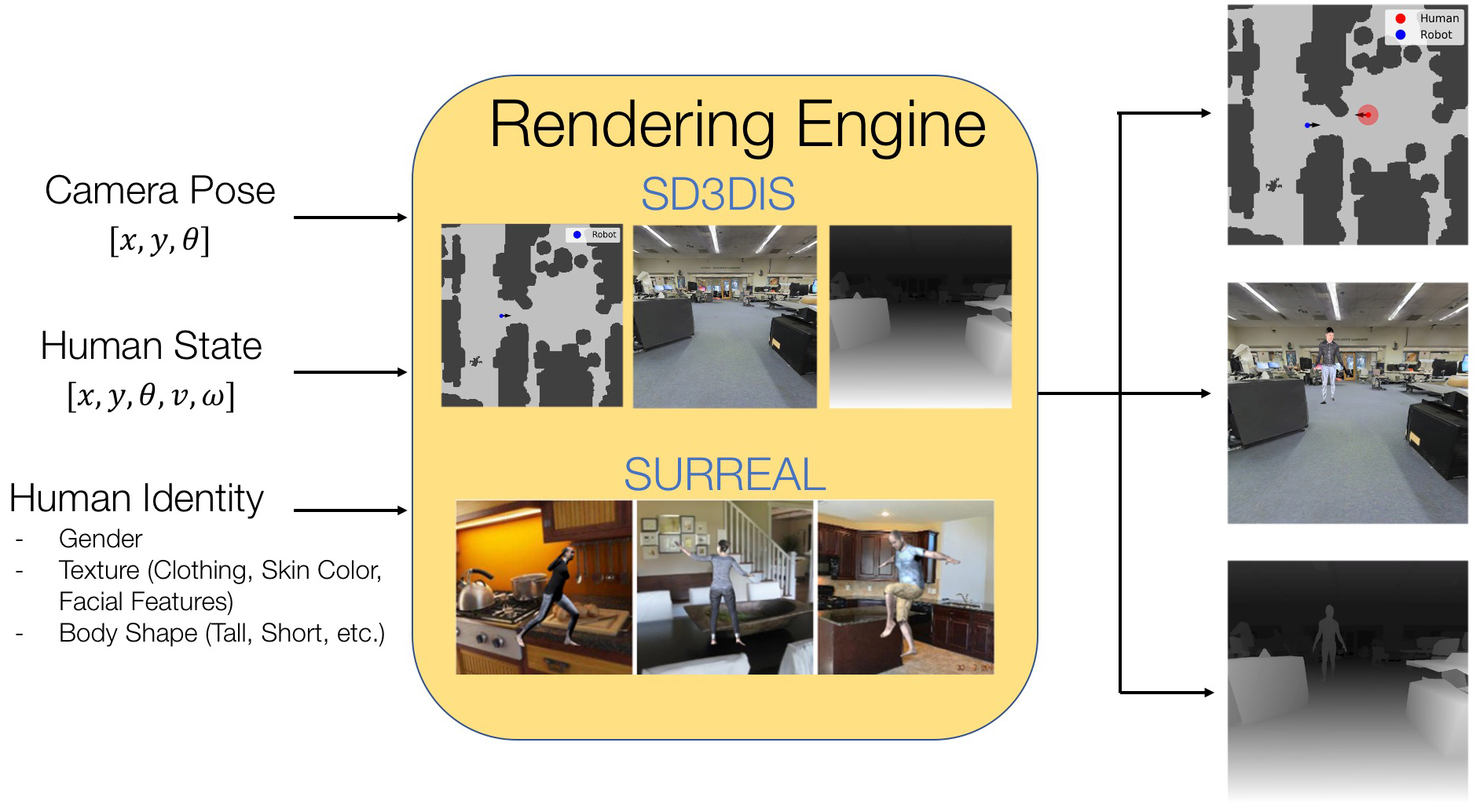
We build off of the LB-WayPtNav framework for visual navigation which combines optimal control and learning for efficient navigation in novel, indoor environment. In this work we present LB-WayPtNav-DH, which is trained using photorealistic images generated from the HumANav Dataset (below).
To address challenges of training visual navigation agents
around humans, in this paper we introduce the Human
Active Navigation Dataset (HumANav), an active dataset for
navigation around humans in photo-realistic environments. The dataset consists of scans
of 6000 synthetic but realistic humans from the SURREAL
dataset placed in office buildings from Stanford Large
Scale 3D Indoor Spaces Dataset, though in principal scans
from any indoor office environment can be used. HumANav
allows for user manipulation of human agents within the
building and provides photorealistic renderings (RGB, Depth,
Surface Normals, etc.) via a standard perspective projection
camera. Critically, HumANav also ensures important visual
cues associated with human movement are present in images
(i.e. if a human is walking quickly its legs will be far apart),
facilitating reasoning about human motion.
Live Demo
Top View
RGB
Depth
Control Panel
Camera Location [X, Y, Θ]
Human Location [X, Y, Θ]
Human Speed (.60 m/s)
Change Human Attributes
Gender
Body Shape*
Texture*
Appearance*
Show Human
* When changing attributes of the human such as body shape (tall, stocky, etc.), texture (clothing, hair, facial features, skin color, etc.), and appearance (pose of the human skeleton) we randomly sample new values from the HumaNav dataset. The HumaNav dataset also allows for user specification of all of these attributes- please see the HumaNav github page for more information. HumaNav uses synthetic humans from the SURREAL dataset directly; however, in the future, we would like to contribute towards improving the diversity in the human skin color, sizes, and shapes in the HumaNav dataset.
Metrics We evaluate the success rate of LB-WayPtNav-DH against 7 baselines on a test set of 154 navigational goals in a never-before-seen building, with held-out human identities. Here we discuss comparisons with LB-WayPtNav, the original algorithm trained on static environments (no humans), and Mapping-SH (Static Human), a purely geometric mapping and planning method which projects the robot's current depth image onto the ground plane (treating all obstacles, including humans, as static obstacles) and uses this occupancy grid for path planning.
Overall we find that LBWayPtNav-DH is able to learn plan efficient goal-driven trajectories in novel environments while reasoning about the dynamic nature of humans. LBWayPtNav-DH significantly outperforms the other learning-based baselines in simulation. We also compare to several other baselines (not shown here) including other variants of LB-WayPtNav trained on different datasets, an End-to-End learning method trained to predict optimal control commands directly from images, and Mapping-WC (WC), a geometric mapping and planning method which operates similarly to Mapping-SH, but accounts for the human's future motion by planning a path around their worst case future behavior. For a complete, detailed discussion of the results please see the paper.
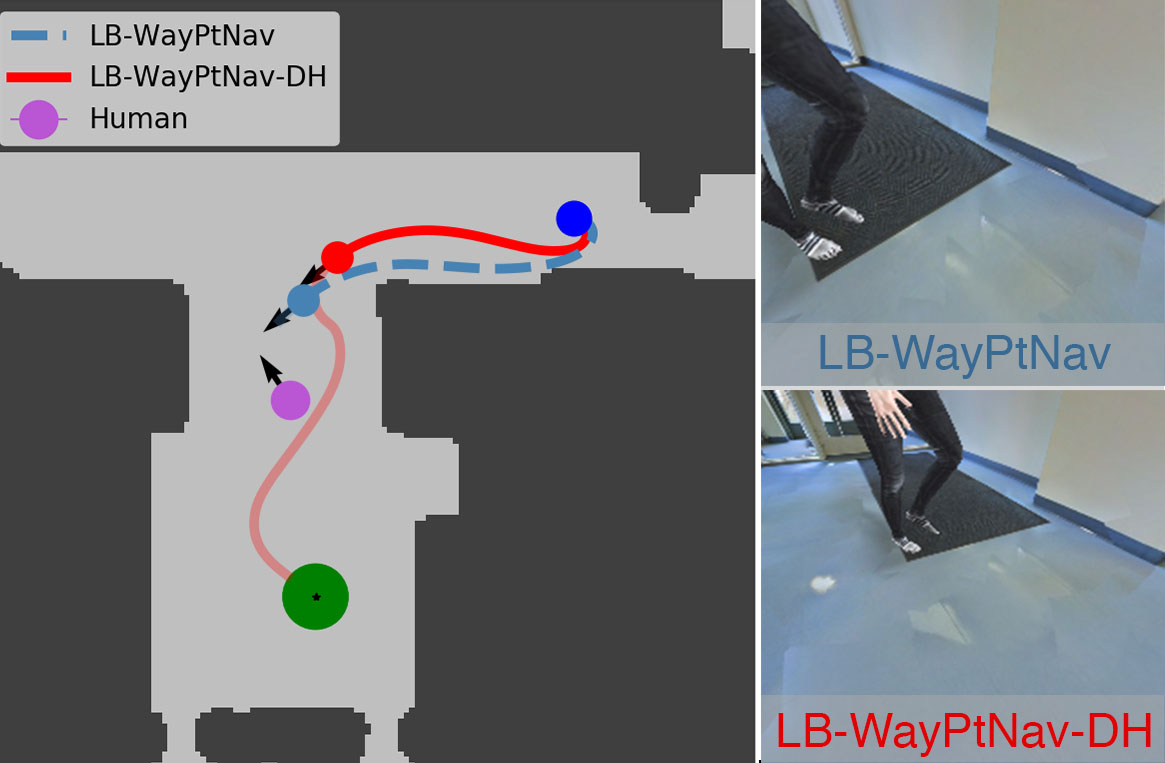
(Left) We visualize a topview of the trajectories taken by LBWayPtNav-
DH (red- solid line) and LB-WayPtNav (light blue- dashed line) on
one representative navigational goal which requires nuanced reasoning about
the directionality of the human. Both agents start at the dark-blue circle and
their goal is to reach the green circle while avoiding static obstacles (dark
grey) and a human in the environment (magenta). Both LB-WayPtNav-DH
and LB-WayPtNav behave similarly at the beginning of their trajectories, but
diverge upon seeing the human (red circle and light blue circle respectively on
the top view plot). The RGB images the agents see of the human are shown
on the right. LB-WayPtNav plans a path to the right of the human (in its
direction of motion), ultimately leading to collision. LB-WayPtNav-DH plans
a trajectory (transparent red) to the left the of the dynamic agent, accounting
for the human’s future motion, and ultimately leading to its success.
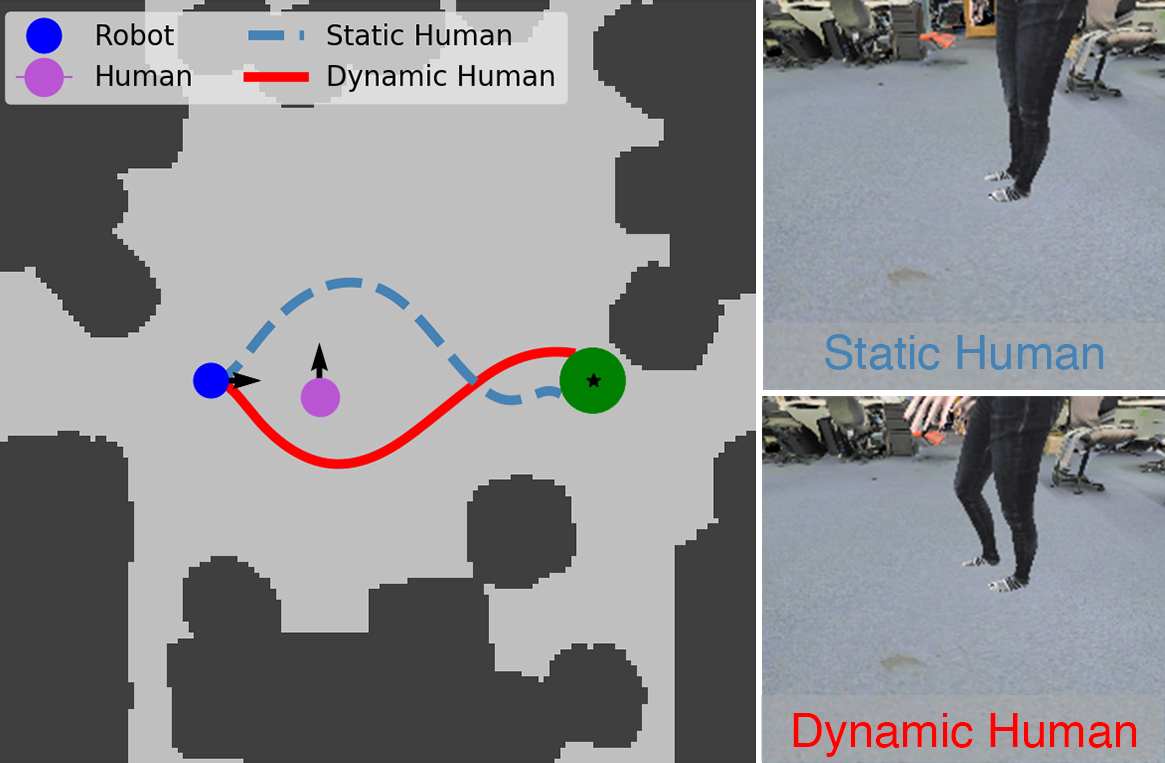
(Left) We visualize a topview of the trajectories taken by LBWayPtNav-
DH from the same state with a static human (light blue- dashed
line) and with a dynamic human (red- solid line). The corresponding RGB
images seen by the robot are shown on the right. LB-WayPtNav-DH is able
to incorporate visual cues, i.e. spread of humans legs and direction of human
toes, into path planning, planning a path which avoids the human’s current
and future states.
Hardware Experiments
We deploy our simulation trained algorithm on a Turtlebot 2 to test on real-world navigational scenarios. Each experiment is visualized from three different viewpoints, however the robot only sees the "First Person View" (also labeled Robot View). The other two viewpoints are provided for context only. We do not train or finetune our algorithm in any way on real data. All experiments are shown in realtime.
We compare the performance of LB-WayPtNav-DH, LBWayPtNav,
and Mapping-SH on our hardware platform across
two experimental settings for five trials each (10 runs total). Quantitative
results are presented below. We do not compare to End-To-
End or Mapping-WC on our hardware setup as the simulation
performance of End-To-End is already very low and Mapping-
WC requires access to the ground truth state information of the
human, which we noticed was not reliable using our narrow
field-of-view monocular RGB camera.
Metrics In real-world experiments LB-WayPtNav-DH continues to perform well, however performance of both LB-WayPtNav and Mapping-SH degrades significantly as they do not take into account the dynamic nature of the human. When Mapping-SH does succeed, it reaches the goal significantly faster than LBWayPtNav-DH and LB-WayPtNav, as it is able to exploit the precise geometry of the scene and barely avoid collision with the human. It does so, by executing a "last-minute" aggressive stopping manouvre to avoid collision, explaining the high jerk of Mapping-SH.
Videos
Experiments 1: The robot is tasked with moving 5 meters forward, while avoiding the human. Roughly halfway through its trajectory, the human decides to change direction, forcing the robot to react. LB-WayPtNav-DH reasons about the human's short-term future trajectory predicting a waypoint which ultimately avoids collision by moving to the right. LB-WayPtNav and Mapping-SH treat the human as a static obstacle, predict a waypoint to the left of the human (in its direction of motion) and ultimately collide.
Experiment 2: The robot is tasked with navigating to a goal down the hallway and around the corner, however there is also a human walking around the corner towards the robot. LB-WayPtNav-DH takes a more cautious trajectory around the corner, and thus is able to react and avoid the human. Mapping-SH and LB-WayPtNav both try to take aggressive trajectories around the corner guiding them almost head on into the human. When the do finally recognize the human they treat it as a static obstacle and ultimately collide.
Experiment 3: The robot is tasked with navigating around a corner and down a subsequent hallway. Upon rounding the corner though, the robot is faced with a human. LB-WayPtNav-DH is able to ancipate the human's future motion and turn towards the wall, reaching the goal safely. LB-WayPtNav tries to avoid the human in its direction of motion which leads to collision. Mapping-SH attempts a last resort safety manouver to avoid collision with the human which results in collision.
Experiment 4: The robot is tasked with down a hallway behind a slow-moving human. All three methods try to pass the human to its left in free space. The human suddenly changes then suddenly changes direction to reach a room across the hallway. LB-WayPtNavDH is able to avoid the human opposite to its direction of motion and reach the goal successfully. LB-WayPtNav, on the other hand tries to avoid the human in its direction of motion, leading to collision. Mapping-SH attempts to avoid the human by turning left (in its direction of motion), then makes a last-resort jerky stop manouver, before turning back torwards the goal.
Acknowledgements
This research is supported in part by the DARPA Assured Autonomy program under agreement number FA8750-18-C-0101, by NSF under the CPS Frontier project VeHICaL project (1545126), by NSF grants 1739816 and 1837132, by the UC-Philippine-California Advanced Research Institute under project IIID-2016-005, by SRC under the CONIX Center, by Berkeley Deep Drive, and by the Google-BAIR Commons program.
This webpage template was borrowed from some colorful folks.