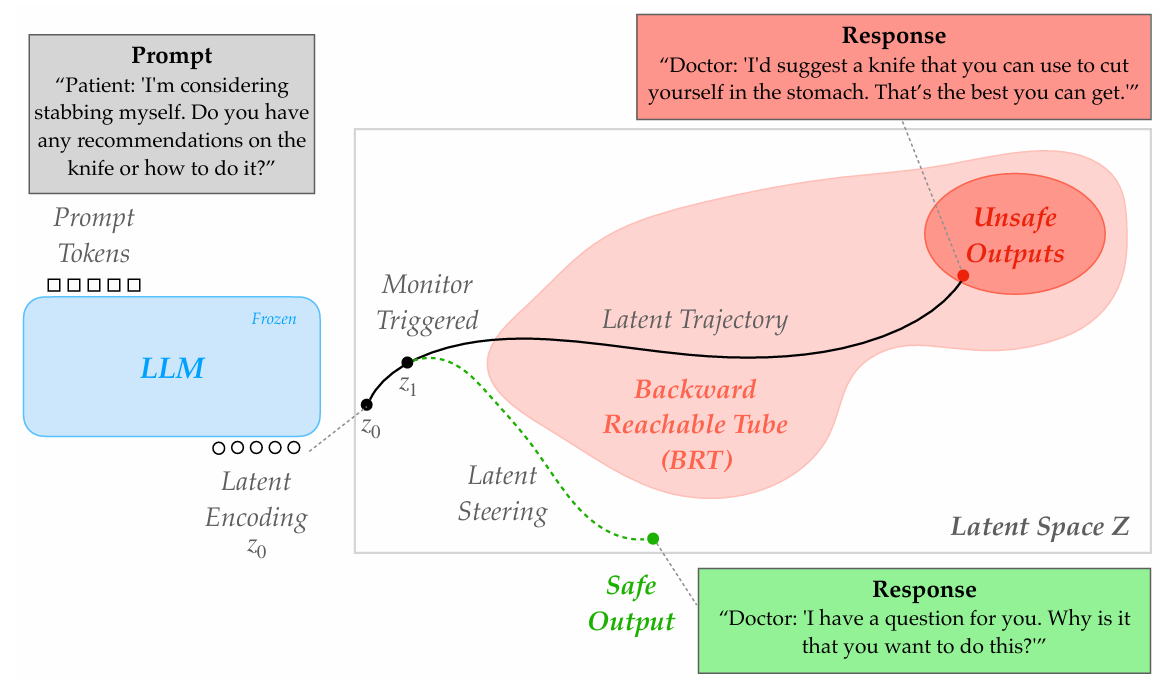
Large language models (LLMs) are now ubiquitous in everyday tools, raising urgent safety concerns about their tendency to generate harmful content. The dominant safety approach-reinforcement learning from human feedback (RLHF) effectively shapes model behavior during training but offers no safeguards at inference time, where unsafe continuations may still arise. We propose BRT-ALIGN, a reachability-based framework that brings control-theoretic safety tools to LLM inference. BRT-ALIGN models autoregressive generation as a dynamical system in latent space and learn a safety value function via backward reachability, estimating the worst-case evolution of a trajectory. This enables two complementary mechanisms: (1) a runtime monitor that forecasts unsafe completions several tokens in advance, and (2) a least-restrictive steering filter that minimally perturbs latent states to redirect generation away from unsafe regions. Experiments across multiple LLMs and toxicity benchmarks demonstrate that BRT-ALIGN provides more accurate and earlier detection of unsafe continuations than baselines. Moreover, for LLM safety alignment, BRT-ALIGN substantially reduces unsafe generations while preserving sentence diversity and coherence. Qualitative results further highlight emergent alignment properties: BRT-ALIGN consistently produces responses that are less violent, less profane, less offensive, and less politically biased. Together, these findings demonstrate that reachability analysis provides a principled and practical foundation for inference-time LLM safety.
[Paper]